
Performing A/B Testing with Python
A/B Testing – also known as Split Testing – is a means of testing a hypothesis using a randomized experiment (variable A vs. variable B) to determine which variable outperforms the other. The metric of performance is individual to the purpose of the experiment being run.
Examples of A/B testing
A company is creating an e-mail campaign and wants to determine which subject header is most effective. They create two different subject headers (A: “Claim your 50% discount”, B: “50% Discount – claim now!”). They send an e-mail with header A to 1000 clients and an e-mail with header B to 1000 clients, with the success metric being click-through rate (CTR), i.e., how many customers click through to claim.
Here are a few more potential options
- Testing different placements of a CTA (call to action) button on a website to see which position gets more clicks
- Experimenting with different product pairs in cross-sell campaigns to see which pairing generates the most revenue for future campaigns
- Comparing different headers, content, or delivery times of emails or social media posts to see which generates the most views or click-throughs
The Project
In the below project, I’ve created fictitious data for a campaign in which the marketing team are trying to determine which headliner and graphics configuration for a sales promotion will generate a high conversion rate. My role is to determine (a) which configuration is more effective, and (b) whether that performance is a result of chance or is indeed due to a being a better variant
The Process
- Loading the data to a data frame
- Summarizing the data to get aggregate values across the month
- Perform a Z-test for proportions
- Conduct a 2-tailed test
- Prepare conclusions
1. Loading the data
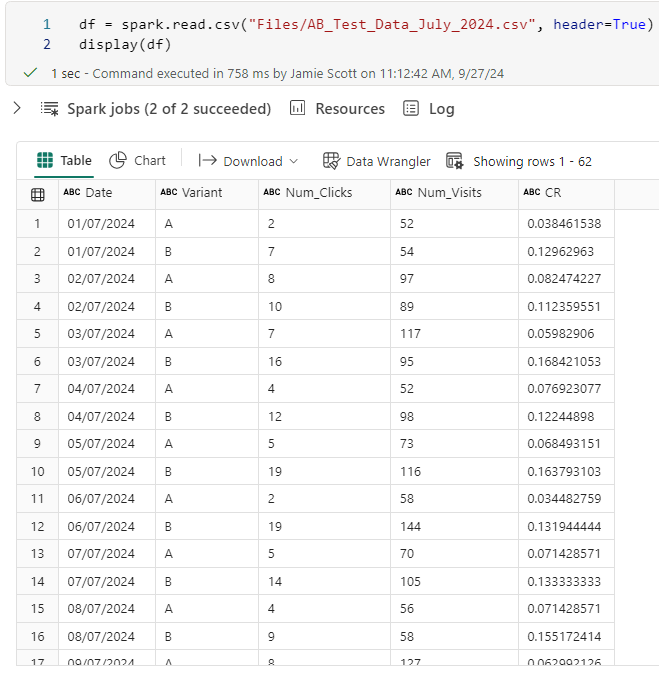
Below you can see a sample of data after it has been loaded from its native CSV format to a python dataframe.
– Variant = A or B
– Num_Clicks is the number of unique users who clicked through to order
– Num_Visits is the number of unique visitors to the page
– CR is the conversion rate (number of clicks over number of visits)
2. Summarizing the data to get aggregate values across the month
Using the below code, we will now have a summarized dataframe that we can use to pull for our proceeding steps and calculations
from pyspark.sql.functions import *
# Grouping by Variant to calculate the total visits, total clicks, and overall conversion rate
summary_df = df.groupBy("Variant") \
.agg(
sum("Num_Clicks").alias("Total_Clicks"),
sum("Num_Visits").alias("Total_Visits")
)
# Calculating the overall conversion rate
summary_df = summary_df.withColumn("Overall_CR", summary_df["Total_Clicks"] / summary_df["Total_Visits"])
# Display the summarized data
display(summary_df)
3. Perform a Z-test for proportions
To calculate the Z-Score, there are a few things we need to:
We first need to calculate the combined proportion, which can be done as:
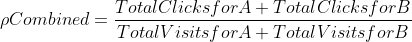
# Extracting the summarized data for each variant
variant_a = summary_df.filter(summary_df["Variant"] == "A").collect()[0]
variant_b = summary_df.filter(summary_df["Variant"] == "B").collect()[0]
# Data from summary
total_visits_A = variant_a["Total_Visits"]
total_visits_B = variant_b["Total_Visits"]
CR_A = variant_a["Overall_CR"]
CR_B = variant_b["Overall_CR"]
# Combined conversion rate (pooled proportion)
p_combined = (CR_A * total_visits_A + CR_B * total_visits_B) / (total_visits_A + total_visits_B)
print(f"Pooled Proportion: {p_combined}")Then we need to calculate the standard error (SE). Below na and nb represent the total visits for variants A and B respectively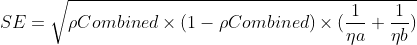
# Calculating the Standard Error (SE)
SE = math.sqrt(p_combined * (1 - p_combined) * ((1 / total_visits_A) + (1 / total_visits_B)))
print(f"Standard Error: {SE}")To get the Z Score, we simply need to do 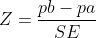
# Calculating the Z Score
Z_score = (CR_B - CR_A) / SE
print(f"Z-score: {Z_score}")In our case the output for each of the pooled conversion, SE and Z-Score are:
Pooled Proportion: 0.1071731388841784
Standard Error: 0.00805661437945441
Z-score: 8.866355994728497
4. Conduct a 2-Tailed test
To run with the 2-Tailed test, we first need to get a P score. We can do this by looking up our Z-Score on a Z-table, but below I’ve gone ahead and calculated this myself in Python. Because this is a 2-Tailed test, I need to calculate the p-value for both sides of the distribution
p_value = 2 * (1 - norm.cdf(abs(Z_score)))norm.cdf(abs(Z_score)) returns the cumulative probability to the absolute value of the Z-score.
1 – norm.cdf(abs(Z_score))) gives the probability in the upper trail
Multiplying by 2 accounts for both tails.
After putting it all together (and making a few adjustments to the code to streamline it), we end up with:
import math
from pyspark.sql.functions import sum as spark_sum, col # Import col here
from scipy.stats import norm
df = spark.read.csv("Files/AB_Test_Data_July_2024.csv", header=True, inferSchema=True)
# Grouping by Variant to calculate the total visits, total clicks, and overall conversion rate
summary_df = df.groupBy("Variant") \
.agg(
spark_sum("Num_Clicks").alias("Total_Clicks"),
spark_sum("Num_Visits").alias("Total_Visits")
) \
.withColumn("Overall_CR", col("Total_Clicks") / col("Total_Visits"))
# Extracting the summarized data for each variant
variant_a = summary_df.filter(col("Variant") == "A").collect()[0]
variant_b = summary_df.filter(col("Variant") == "B").collect()[0]
# Data from summary
total_visits_A = variant_a["Total_Visits"]
total_visits_B = variant_b["Total_Visits"]
CR_A = variant_a["Overall_CR"]
CR_B = variant_b["Overall_CR"]
# Combined conversion rate (pooled proportion)
p_combined = (CR_A * total_visits_A + CR_B * total_visits_B) / (total_visits_A + total_visits_B)
print(f"Pooled Proportion: {p_combined}")
# Calculating Standard Error
SE = math.sqrt(p_combined * (1 - p_combined) * ((1 / total_visits_A) + (1 / total_visits_B)))
print(f"Standard Error: {SE}")
# Calculating the Z-score
Z_score = (CR_B - CR_A) / SE
print(f"Z-score: {Z_score}")
# Calculating the p-value
p_value = 2 * (1 - norm.cdf(abs(Z_score)))
print(f"P-value: {p_value}")
Output:
Pooled Proportion: 0.1071731388841784
Standard Error: 0.00805661437945441
Z-score: 8.866355994728497
P-value: 0.0
5. Conclusions
Let’s take a look at each of the output elements and understand what they mean.
Pooled Proportion (0.107). The pooled proportion represents the combined conversion rate of both variants across all visits. The PP rate of 0.107 suggests that on average, around 10.7% of the total visits resulted in clicks.
Standard Error (0.0081). The SE measures the variability between the two conversion rates. A smaller SE value suggests that the estimate of the CR difference is very precise, which is common with larger sample sizes.
Z-Score (8.87). The Z-score indicates how many standard deviations the difference between A and B’s CRs are from the expected difference (if there wasn’t a real difference). A Z-score of 8.87 is extremely high, which suggests a very large and statistically significant diference between the two variants.
P-value (0.0). A p-value of 0.0 (or maybe more realistically, <0.0001) basically suggests the difference between the 2 variants is extremely unlikely to be the result of chance. Usually we look at significance levels of 0.05 or 0.01.
Given an extremely high Z-score and a p value of basically 0, we could conclude from these results with a high degree of confidence that variant B is statistically significantly better than variant A.
Now of course, this data was put together with the intention of showing a clear difference between variant A and B. In real world scenarios, we’re not likely to see such a clear distinction.
Typically, if the p-value <= 0.05 (for a 95% confidence), we'd reject the null hypothesis, indicating a statisticaly significant difference between A and B, whereas if the p value was >0.05, it’d indicate no real evidence to claim a difference.
Leave a Reply